SELECT LENGTH('🙆♀️')= 4 ←???
LENGTH関数を絵文字に使うと発生する問題
LENGTH関数は一部の絵文字や外国語(書記素クラスタ)を正しくカウントできない。
絵文字だけならともかく、フランス語や韓国語などのメジャーな言語でも問題は発生する。
解決策
正確性が必要な場合、PythonなどのUDFでカウントする必要がある。
以下のように正しく文字列をカウントするUDFを作る。
CREATE OR REPLACE FUNCTION COUNT_GC(s varchar)
returns number
language python
runtime_version = 3.11
packages = ('pyicu')
handler = 'count_grapheme_clusters'
as $$
import icu
def count_grapheme_clusters(s):
iter = icu.BreakIterator.createCharacterInstance(icu.Locale("ja_JP"))
iter.setText(s)
return sum(1 for _ in iter)
$$;実験
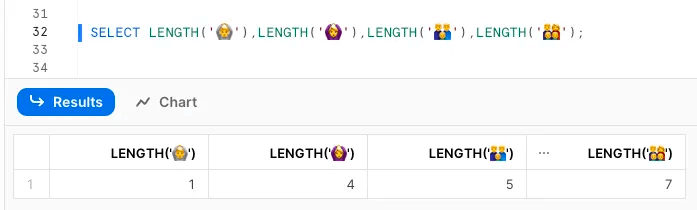
絵文字や外国語の文字数を測ってみた。面白い。

OCTET_LENGTHは半角文字は1文字1バイト、全角文字は1文字3バイト(日本語)、絵文字は1文字4バイトという認識が一般的ですが、書記素クラスタの前には無力です。

UDFでカウントしたときだけ正しい結果が得られます。

なぜこんなことになるのか
書記素クラスタをLENGTH関数が正しくカウントしないからです。
Unicodeには複数のUnicode文字(コードポイント)から作成された文字があり、これを書記素クラスタ(Grapheme clusters)と呼びます。
書記素クラスタの例
- "🙆" 1コードポイント
- "U+200D" 1コードポイント
- "♀" 1コードポイント
- "U+FE0F" 1コードポイント
=> 🙆♀️ 4コードポイント
Unicodeの標準によると書記素クラスタは1文字として表示し、1文字としてカウントすべきとされています。[1]
プログラマがユーザーに文字数を提供する必要がある場合、その数は書記素クラスタの境界によって区切られたセグメントの数に対応するべきです。
しかし、追加の実装なしで対応できるフレームワークはほとんどないのが現状です。
Python3.11のlen関数もコードポイントの数で出力されます。
現状では、絵文字や外国語を含むカラムの文字数を正確にカウントするにはUDFが必要です。
結論
文字列をカウントするときには、絵文字や外国語が含まれていないかどうかに注意。
追記
Polar Bearは4だった🫠
SELECT LENGTH('🐻')=1
SELECT LENGTH('🐻❄️')=4おすすめの記事
UDFでユーザー管理のキャッシュ領域がほしい
/tmpと/dev/shmが使えた。Snowpark Optimized Warehouseに新たなユースケースを見出したかもしれない。
GA4もSnowflakeで分析する時代がついに来たぞ!
2024年1月29日、GA4とSnowflakeの公式コネクタがリリースされました。従来のソリューションと比較してGA4コネクタの何が素晴らしいのかを解説し、試用の際の注意点を記載しました。
SnowflakeでAWS S3 Express One Zoneを使うとどれだけ速いのか
SnowflakeにS3 Express One Zoneで外部ステージを作成してみました。読み取りワークロードでは、最大16%ほどクエリが高速化していました。
Snowflakeのワーカーノードがアップグレードされていた!
Snowflakeのワーカーノードのスペックが大幅アップグレードされてました。ローカルディスクは2倍に、CPUはx86_64からaarch64(Graviton2 )に変わっていました。